









KPMG voulait montrer comment l’intelligence artificielle transforme déjà les grandes entreprises. Son rapport a surtout montré autre chose : une IA peut produire des preuves fausses, les rendre crédibles, puis les faire circuler dans des documents utilisés par des décideurs. Les politiques de santé publique se baseront-elles bientôt sur des données erronées ?
Ce qu’il faut retenir
- KPMG, cabinet d’audit mondialement connu, a utilisé l’IA pour l’un de ses rapports ;
- Le rapport contenait de nombreuses sources erronées, déformées ou invérifiables ;
- L’omniprésence de l’IA force aujourd’hui à une meilleure compréhension de son fonctionnement, et à son utilisation de manière raisonnée dans le cadre de la recherche publique.
Quand l’IA fabrique des preuves pour KPMG
 Pourquoi parler d’intelligence artificielle sur le Vaping Post ? Simplement, car le 12 juin 2026, la société GPTZero, dont le produit phare est un détecteur d’hallucinations, a épinglé un rapport produit par KPMG, l’un des Big Four de l’audit. Aux côtés de Deloitte, EY et PwC, KPMG propose plusieurs types de services : de l’audit financier aux services de consulting, en passant par les thèmes de la transformation digitale, de la fiscalité, des stratégies, etc. Les Big Four auditent ou conseillent une grande partie des plus grands groupes mondiaux, et leurs rapports circulent aussi dans les milieux politiques et administratifs.
Pourquoi parler d’intelligence artificielle sur le Vaping Post ? Simplement, car le 12 juin 2026, la société GPTZero, dont le produit phare est un détecteur d’hallucinations, a épinglé un rapport produit par KPMG, l’un des Big Four de l’audit. Aux côtés de Deloitte, EY et PwC, KPMG propose plusieurs types de services : de l’audit financier aux services de consulting, en passant par les thèmes de la transformation digitale, de la fiscalité, des stratégies, etc. Les Big Four auditent ou conseillent une grande partie des plus grands groupes mondiaux, et leurs rapports circulent aussi dans les milieux politiques et administratifs.
En octobre 2025, KPMG a publié son rapport annuel sur l’excellence de la relation client (Customer Experience Excellence). Basé sur plus de 80 000 interviews menées auprès des consommateurs, le rapport couvre plus de 2 600 marques. Sa dernière édition était baptisée Total Experience: Redefining Excellence in the Age of Agentic AI. Elle démontrait que les grandes entreprises du monde entier avaient d’ores et déjà adopté l’IA pour améliorer l’expérience client.
Problème, dans la quatrième partie de ce rapport, qui présente des études de cas par pays, donc des exemples d’entreprises dans le monde qui ont adopté l’intelligence artificielle, sur 45 références citées par KPMG, 40 sont erronées, déformées, ou invérifiables.
Par exemple, le rapport cite un communiqué de presse de 2019 pour prouver que Japan Railways utilise l’intelligence artificielle pour recommander des voyages et prédire des perturbations. Sauf que le communiqué date de 2019, ne mentionne pas l’IA, et précède de plusieurs années la disponibilité commerciale des systèmes aujourd’hui présentés comme de l’agentic AI. Il affirme aussi que la compagnie aérienne Emirates a adopté un chatbot mobile nommé Sara, capable de modifier des réservations de vol. Sauf que Sara est un robot physique et non un chatbot, et qu’il n’a absolument pas la capacité de modifier de quelconque réservation. Tout aussi aberrant, le rapport cite une recherche menée par le cabinet KPMG lui-même, qui indiquerait que l’IA serait la priorité d’investissement numéro un pour 55 % des PDG. Alors que cette recherche, publiée le même mois, avance en réalité le chiffre de 71 %. KPMG a depuis retiré le rapport de son site, déclarant « examiner les circonstances de sa publication ».
KPMG n’est pas le seul cabinet à s’être fait épingler. Deloitte, EY, et divers cabinets d’avocats ont commis la même erreur. Mais le fait qu’un rapport censé démontrer les bénéfices de l’IA soit lui-même le fruit d’une IA mal supervisée offre une saveur particulière à cette histoire.
Une IA ne comprend pas le sens des mots
Pour comprendre comment un rapport produit par l’un des plus grands cabinets de conseil au monde peut contenir autant de références douteuses, il faut revenir à ce que fait réellement une intelligence artificielle (IA) générative. Malgré ce que son nom laisse entendre, elle n’est munie d’aucune « intelligence ». En fait, une IA n’a pas la moindre idée de ce que vous lui demandez, ni de ce qu’elle vous répond.
ChatGPT, Gemini, Claude, Grok, Llama et consort sont des LLM, l’acronyme de Large Language Model. Ce type d’intelligence artificielle n’est entraîné que sur une seule tâche : prédire quel token vient ensuite.
Un token est une unité de texte. Il prend parfois la forme d’un mot, d’un bout de mot, d’une ponctuation, d’un espace, etc. Par exemple, le mot « bonjour » est un token. Le mot « intelligence » en est peut-être quatre (in-tel-li-gence). La seule capacité d’une IA est de prédire quel token vient après le précédent.
Pour y parvenir, une IA a reçu un entraînement durant lequel elle a ingéré des centaines de milliards de tokens provenant de livres, de forums internet, de Wikipédia, d’articles scientifiques, de manuels d’utilisation, etc. Plus ou moins tout ce qui existe sous forme de texte sur la planète. Lorsqu’un utilisateur interagit avec une intelligence artificielle, plusieurs milliards de paramètres numériques s’activent pour donner un « poids » à chaque token et ainsi calculer quels sont les tokens qui ont le plus de probabilité de venir ensuite.
Prenons un exemple. Si l’utilisateur d’une IA lui demande quelle est la capitale de la France, la machine lui répondra Paris. Mais l’intelligence artificielle ne comprend ni la question ni la réponse qu’elle donne. Elle ne sait pas ce qu’est la France, ce qu’est une capitale, et elle ne connaît pas Paris. Elle sait simplement que, dans les milliards de tokens qu’elle a ingérés lors de son entraînement, le token « Paris » apparaît très souvent aux côtés des tokens « capitale » et « France ». Il y a donc de fortes probabilités que, lorsqu’un utilisateur lui envoie une phrase contenant les tokens « capitale » et « France », le token à répondre soit « Paris ».
Bien sûr, cette explication est simplifiée. La réponse « Paris » à la question « quelle est la capitale de la France ? » ne dépend pas que d’une association. Pour prédire les tokens à répondre, le contexte entre également en ligne de compte. Dans le cas de cette question, le schéma de fonctionnement d’une IA pourrait être illustré de la manière suivante : le mot « capitale » est associé à des centaines de villes du monde. Le mot « France » est associé à tout un tas d’autres mots. Mais seul le mot « Paris » est associé aux deux. Ce mot devient alors statistiquement plus puissant que les autres, et c’est donc celui-ci que l’IA répond.
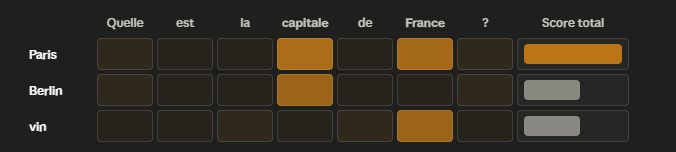
L’illustration ci-dessus représente de manière simplifiée le fonctionnement d’une intelligence artificielle à la question « quelle est la capitale de France ? ». Lorsque l’utilisateur pose cette question, l’IA calcule simultanément vers quel token pousse chaque mot de la question. Dans cet exemple, le mot « capitale » pousse autant les tokens « Paris » et « Berlin ». Mais le mot « France », quant à lui, ne pousse que le token « Paris ». Ce dernier se retrouve donc avec plus de probabilités que le token « Berlin ». Puisque « Paris » est plus probable que « Berlin », l’IA répond Paris. Naturellement, il s’agit là d’une illustration simplifiée, puisque cette opération est réalisée simultanément avec des milliards de tokens.
Le mécanisme qui vient d’être décrit pour « Paris » repose sur des tokens que l’IA a déjà rencontrés des millions de fois lors de son entraînement. Dans ce contexte, c’est uniquement leur combinaison qui est nouvelle. Mais ce même mécanisme de prédiction statistique fonctionne également sur des mots que l’IA n’a jamais rencontrés.
Prenons un nouvel exemple : si on demande à une IA de conjuguer un verbe qui n’existe pas, disons « fleurgir », à la troisième personne du singulier de l’imparfait, elle répondra sans hésiter « il fleurgissait ».
Elle n’a jamais vu ce mot. Elle ne sait pas ce qu’il signifie, et il ne signifie d’ailleurs rien du tout. Mais elle a ingéré des millions de verbes en « -ir » conjugués à l’imparfait, et elle a généralisé le motif : « -ir » devient « -issait ». Le résultat donne l’impression que l’IA a compris une règle de grammaire. Il n’en est rien. Elle n’a fait qu’appliquer une structure statistique à une suite de lettres qu’elle n’avait jamais vue. Elle repère simplement que de nombreux verbes proches, comme fleurir, rougir ou grandir, donnent à l’imparfait des formes en « -issait ». « Fleurgir » ressemble à cette famille, donc « fleurgissait » devient statistiquement plausible. Alors, elle répond « fleurgissait ».
Les hallucinations de l’IA
Ce mécanisme de prédiction explique directement ce que les spécialistes appellent « hallucinations ». Les hallucinations sont des erreurs commises par l’intelligence artificielle : par exemple, prêter une citation à la mauvaise personne ou au mauvais document, ou tout simplement inventer une information qui n’existe pas. Précisément ce qui s’est produit dans le cadre du rapport de KPMG.
Illustrons avec un nouvel exemple. Si une IA a ingéré des milliers d’articles médicaux durant son entraînement, elle a en mémoire des milliers de citations d’études scientifiques. Les citations prennent souvent la même forme, par exemple : Servet, A. (2026). Aspirin and cardiovascular prevention. New England Journal of Medicine, 342(3), 45-67. La forme de cette citation est parfaite. De nombreuses citations d’études scientifiques respectent effectivement ce format. L’enchaînement de tokens correspond donc exactement à celui d’une véritable étude sur l’aspirine.
Si un utilisateur questionne une intelligence artificielle sur les effets cardiovasculaires de l’aspirine, elle pourra tout à fait, dans les sources qu’elle indique, inscrire cette citation. Mais cette étude existe-t-elle réellement ? Absolument pas. L’intelligence artificielle en a-t-elle conscience ? Encore moins. Que cette recherche existe ou non, elle ne s’en préoccupe pas. La seule chose pour laquelle elle est programmée, c’est prédire un enchaînement de mots. Et qu’importe si la phrase ou la citation qu’ils forment est vraie ou non.
Dans le cas présent, l’intelligence artificielle n’aura fait que ce pour quoi elle a été programmée : enchaîner une suite de tokens sur le sujet de l’aspirine, et, lorsqu’on l’interrogera sur la source de ses dires, présenter une nouvelle suite de tokens prenant la forme d’une citation scientifique.
Une dernière question se pose alors : puisqu’une IA ne fait qu’enchaîner des tokens qui forment des mots, puis des phrases, qui parfois sont faux ou ne veulent absolument rien dire, comment se fait-il que les intelligences artificielles n’hallucinent pas en permanence et répondent parfois correctement ? La réponse vient des tokens ingérés durant son entraînement.
Par exemple, si l’utilisateur demande à l’intelligence artificielle de lui citer l’étude la plus importante sur le deep learning, toutes les IA répondront : Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. “Deep learning.” Nature, 521:436–444, 2015.
Pas parce que l’IA « sait » ou « connait » cette étude. Mais parce qu’il s’agit tout simplement de l’étude scientifique sur le deep learning la plus citée de l’histoire, et qu’à force de l’avoir ingérée durant son entraînement, l’enchaînement de tokens qui forment la citation exacte a un poids bien supérieur à un quelconque autre enchaînement qui formerait une citation erronée.
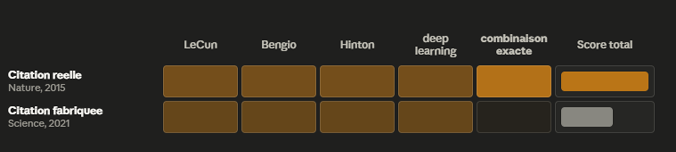
Cette illustration montre que pour les noms d’auteur et le sujet deep learning, la véritable citation et une citation inventée obtiennent le même score de probabilité. Mais la vraie citation a été ingérée des milliers de fois sous une forme précise : « auteurs + titre + revue + année », dans cet ordre. Cette répétition de la séquence donne un poids massif à la vraie citation pour la colonne « combinaison exacte ». La citation inventée, elle, n’est jamais apparue dans cet ordre. Elle ne remporte donc pas de poids pour ce critère. La vraie citation obtient donc un score plus élevé, et c’est celle-ci qui est citée par l’IA.
Des données corrompues pour des décisions réelles
À une époque, lorsqu’une information fausse était publiée, que ce soit par un média, un cabinet, ou toute autre entité, il suffisait de faire un erratum. Les quelques personnes qui avaient lu l’information erronée étaient prévenues de l’erreur, et la vérité était rétablie. Mais à l’ère de l’intelligence artificielle, les choses sont bien plus compliquées.
Le rapport de KPMG est resté en ligne plusieurs mois. GPTZero a documenté que ChatGPT et Gemini le citent déjà comme source fiable, propageant ses informations fabriquées dans d’autres conversations, d’autres rapports, et d’autres décisions. Et l’erratum traditionnel n’existe pas pour ce type de contamination. Qu’une IA l’ait ingéré lors de son entraînement ou qu’elle le retrouve via une recherche web, le rapport KPMG circule désormais comme source fiable. Et dans le premier cas, il est aujourd’hui impossible de retirer une information d’un modèle déjà entraîné. Ce procédé, baptisé “machine unlearning” occupe de nombreux chercheurs, qui n’ont pas encore trouvé de solution.
Ce mécanisme est particulièrement préoccupant dans le domaine des politiques publiques et de la régulation. Pour prendre des décisions, les décideurs du monde entier s’appuient sur les rapports de cabinets de conseil comme base documentaire. La contamination de ces rapports par des données erronées ou hallucinées par des IA constitue un risque systémique pour la qualité de la décision publique.
La législation du vapotage n’y échappe pas. Alors que l’Union européenne se penche actuellement sur la révision de la Tobacco Products Directive (TPD), qu’arrivera-t-il si certains des rapports utilisés contiennent des données fausses ou inventées ? Et le risque que ce soit déjà le cas existe bel et bien. Lors de leur entraînement, les IA ayant ingéré un grand nombre d’études scientifiques, il y a de fortes probabilités que, parmi elles, plusieurs aient été rétractées depuis.
Fin janvier 2026, une recherche liant vapotage et risque d’AVC a été rétractée. Mi-mars 2026, c’était au tour d’une revue systématique qui liait l’utilisation d’une cigarette électronique à un risque de cancer. En juin 2026, c’était un travail qui indiquait un risque plus élevé de BPCO chez les vapoteurs que chez les fumeurs qui était retiré. La plupart de ces études ayant nécessité plusieurs années avant d’être rétractées, il y a fort à parier que leurs données, totalement fausses, ont servi à entraîner des intelligences artificielles, qui présentent désormais leurs conclusions comme fiables.
Aujourd’hui, comprendre comment fonctionne l’intelligence artificielle ne relève plus de la simple curiosité technophile ou de l’apanage de quelques geeks. Connaître les forces et les faiblesses de l’IA est devenu une condition nécessaire à l’évaluation de la fiabilité des sources sur lesquelles reposent nos décisions, y compris les plus importantes. Y compris celles qui impactent la vie de millions de gens.
Dans le reste des news de la cigarette électronique
De Hon Lik à JNR : la délicate question du...

Le marketing de la vape est un sujet délicat à manier. Tout allait sur de bons rails, jusqu’à ce que la vape construise elle-même un mur au milieu de la voie.
Les “smart vapes” pourraient-elles servir à espionner les vapoteurs ?

Des sénateurs américains et un député britannique s’inquiètent des “smart vapes” chinoises, accusées de pouvoir collecter des données sensibles.
La vie courte mais rigolote de Jean-Kevin

Le monsieur de l’article du vendredi a eu une vision du futur qu’il s’empresse de vous partager pour ne pas vous faire rire.


